How I'd Design a URL Shortener on AWS — and What Most Tutorials Get Wrong
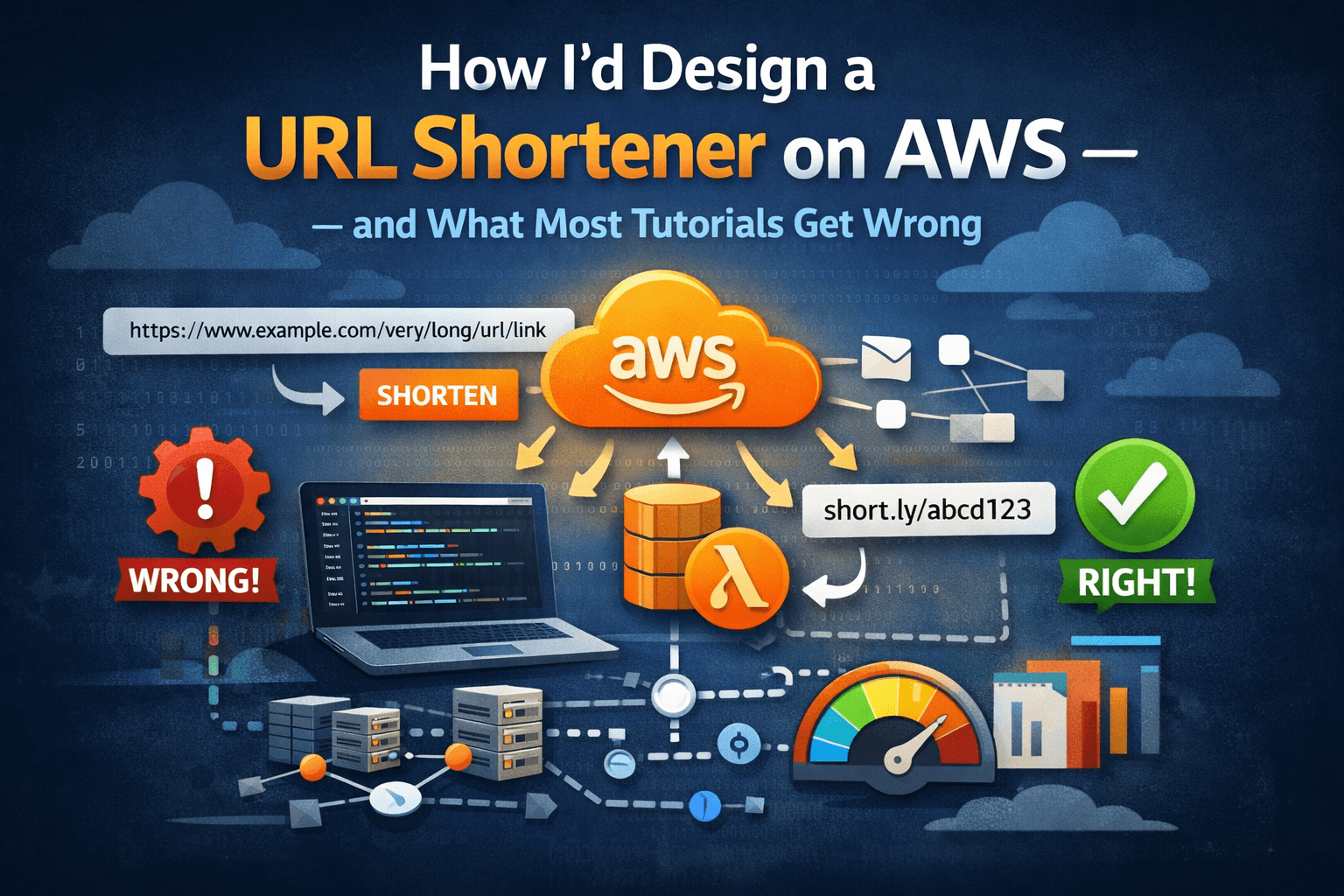
The Problem With Most URL Shortener Tutorials
Search "URL shortener system design" and you'll find hundreds of articles. Most of them give you the same thing: a single server, a database with a short_code column, and a redirect endpoint.
That works for a demo. It doesn't work for production.
The real challenge isn't building a URL shortener. It's building one that handles millions of redirects per day, stays available when things go wrong, and doesn't cost a fortune to run. Those constraints change every decision you make.
Here's how I'd actually design it on AWS — and the tradeoffs I'd make along the way.
Requirements First
Before touching architecture, let's be explicit about what we're building.
Functional requirements:
Given a long URL, generate a short code (e.g.
sho.rt/xK92p)Given a short code, redirect to the original URL
Short codes should be unique and ideally human-readable enough to share
Optional: custom aliases, expiry dates, click analytics
Non-functional requirements:
Reads (redirects) massively outnumber writes (URL creation) — think 100:1 ratio
Redirect latency must be low — under 50ms ideally
High availability — if this goes down, every link on the internet that uses it breaks
Short codes must not collide
These constraints drive every architectural decision below.
The Naive Approach (And Why It Fails)
Most tutorials suggest this:
User → Web Server → Database (lookup short_code) → Redirect
Simple. Works at a low scale. Falls apart fast because:
Every redirect hits the database — at 10,000 requests/second, your DB is the bottleneck
Single server = single point of failure
No geographic distribution — users in Sydney hitting a server in us-east-1 get 200ms+ latency
Let's fix all of this.
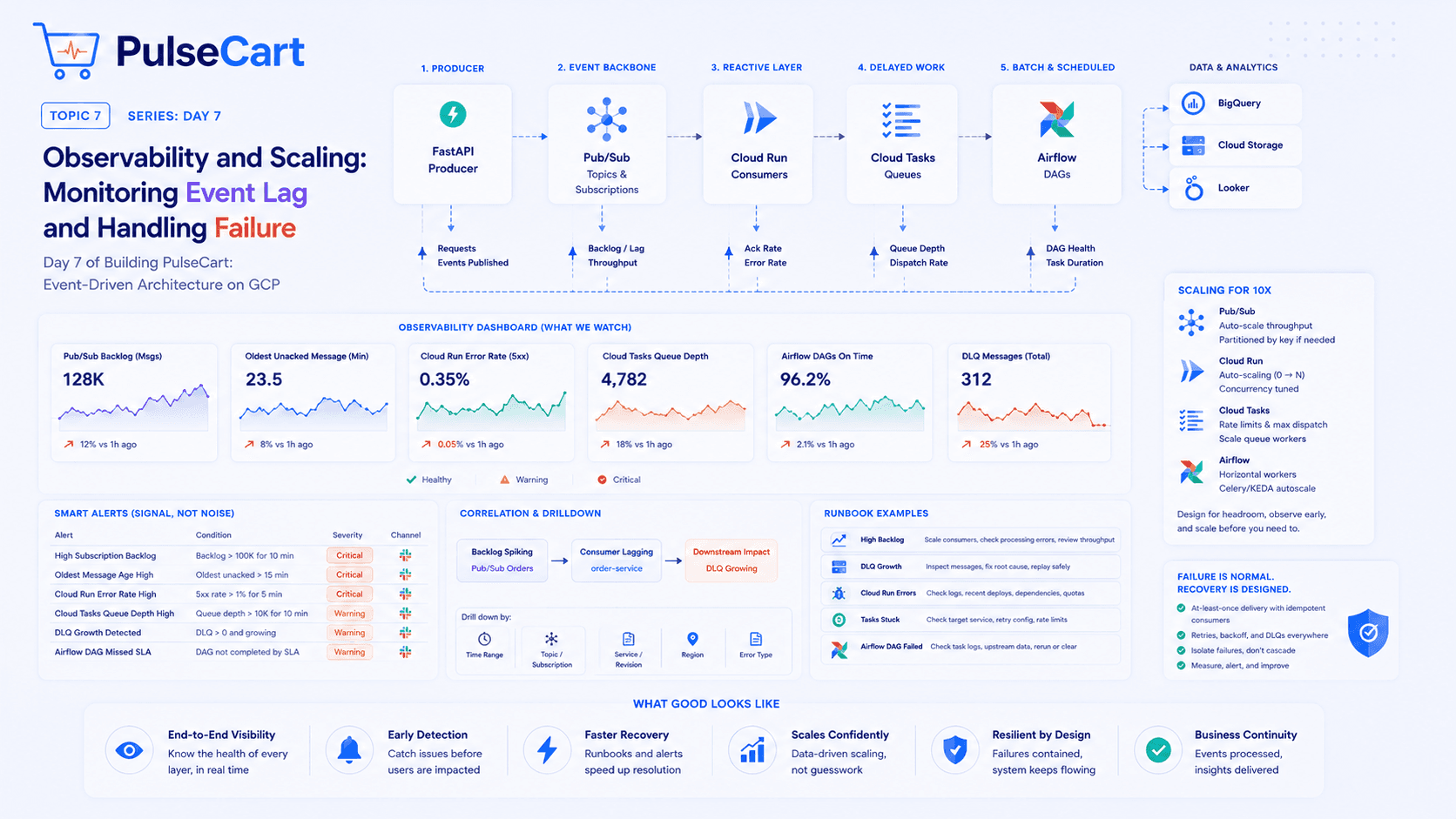
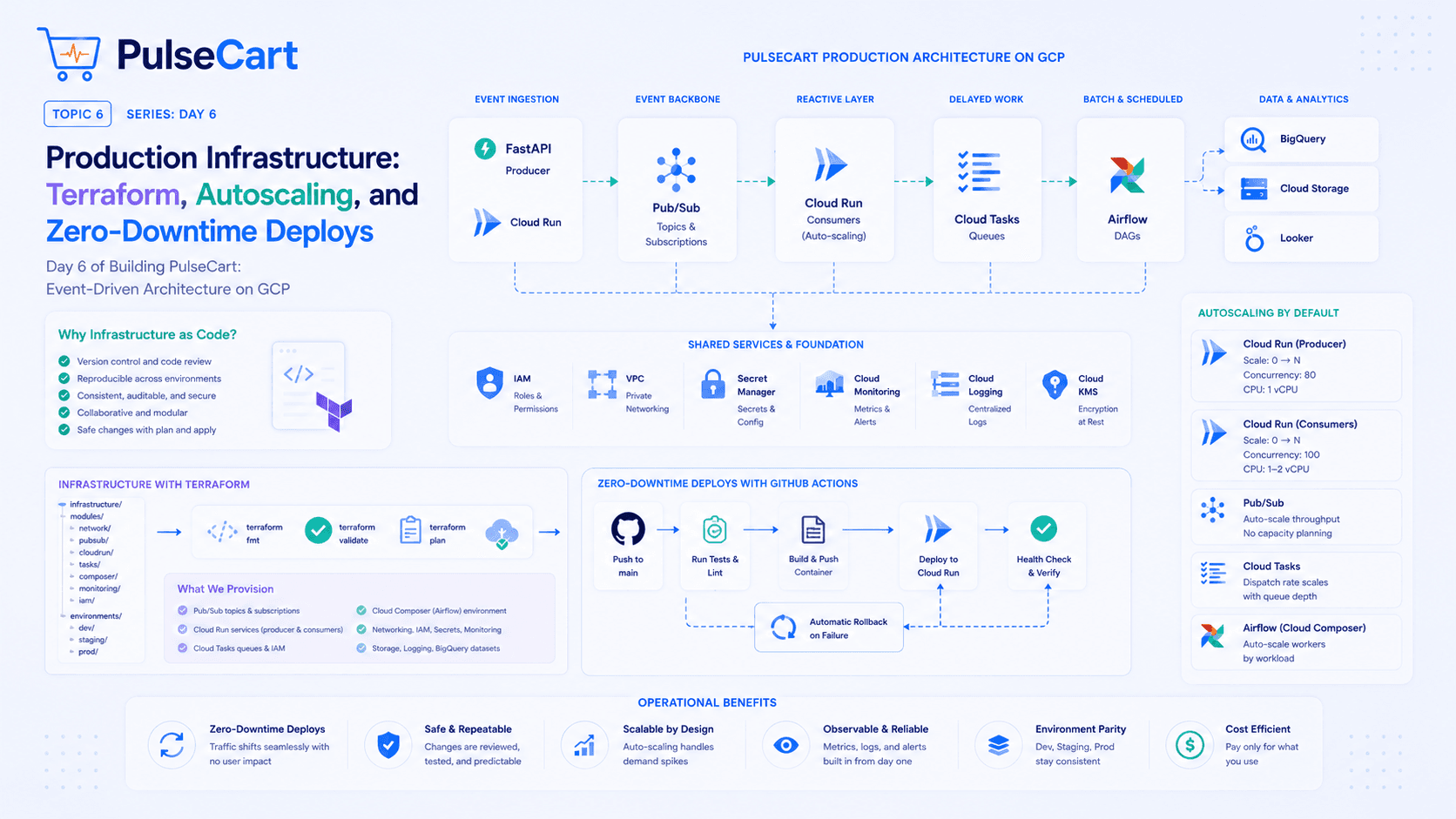
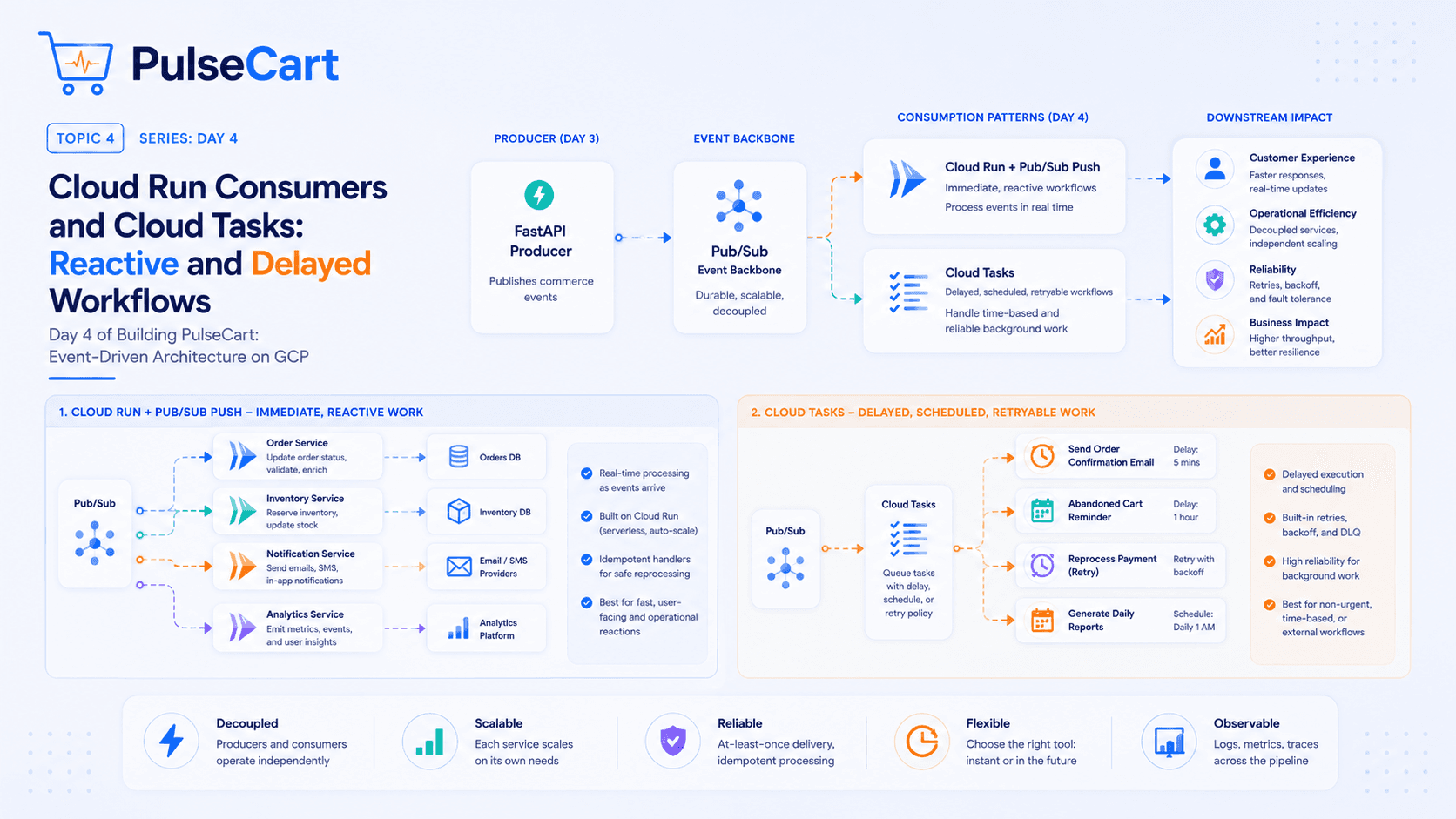
The Architecture I'd Actually Build
Here's the high-level design:
User
│
▼
CloudFront (CDN + Edge Caching)
│
▼
API Gateway
│
├──► Lambda (URL Creation) ──► DynamoDB
│
└──► Lambda (URL Redirect) ──► ElastiCache (Redis)
│
└──► DynamoDB (cache miss)
Let me walk through each component and the reasoning behind it.
Component Breakdown
1. CloudFront — Your First Line of Defense
CloudFront sits in front of everything. For a URL shortener, this is critical because:
Redirects for popular URLs get cached at the edge — a link that goes viral serves millions of requests without ever hitting your origin
400+ edge locations globally mean low latency for everyone
Built-in DDoS protection via AWS Shield Standard
The cache key matters here. You want to cache on the short code, not the full URL. Set a short TTL (30-60 seconds) for most URLs, longer for ones you know won't change.
One important caveat: don't cache 301 redirects. Browsers cache 301s permanently, which means if you ever need to update a destination URL, users with cached responses are stuck. Use 302 (temporary redirect) instead — CloudFront caches it, browsers don't.
2. Short Code Generation — The Part Everyone Gets Wrong
This is where most designs fall apart. Common approaches:
Option A: Auto-increment ID + Base62 encoding
Take a database sequence (1, 2, 3...), encode it in Base62 (0-9, a-z, A-Z), and get short codes like b, c, 1a, 1b.
Problems:
Sequential codes are predictable — someone can enumerate all your URLs
Requires a centralised counter — creates a bottleneck
Option B: Random UUID + truncate
Generate a UUID, take the first 7 characters. Simple. But collision probability increases as your dataset grows, and you need collision checks on every write.
Option C: What I'd actually use — Snowflake-style ID + Base62
Generate a time-ordered unique ID (similar to Twitter's Snowflake) and encode it. You get:
Roughly time-ordered codes (good for debugging)
Extremely low collision probability without a central counter
7-character codes that support ~3.5 trillion unique URLs
On AWS, you can implement this in Lambda with a combination of timestamp + random bits + worker ID (derived from the Lambda execution environment).
3. DynamoDB — The Right Database for This Problem
Why DynamoDB over PostgreSQL or MySQL?
Access pattern is simple: you're almost always looking up by
short_code. DynamoDB is optimised for exactly this.Scales horizontally without configuration — you don't manage sharding
Single-digit millisecond latency at any scale
On-demand capacity means you only pay for what you use — perfect for spiky traffic
Table design:
Table: urls
Partition Key: short_code (String)
Attributes:
- original_url (String)
- created_at (Number — Unix timestamp)
- expires_at (Number — TTL attribute, DynamoDB auto-deletes)
- created_by (String — user ID if authenticated)
- click_count (Number — updated asynchronously)
Set expires_at As your TTL attribute and DynamoDB handles expiry automatically — no cron jobs needed.
4. ElastiCache (Redis) — Making Redirects Fast
Even DynamoDB at ~5ms is too slow if you want sub-50ms redirects globally. The solution: cache the short_code → original_url mapping in Redis.
Cache strategy: Cache-aside (lazy loading)
1. Request comes in for /xK92p
2. Check Redis — cache hit → redirect immediately (~1ms)
3. Cache miss → query DynamoDB → cache result → redirect (~10ms)
What to cache: Only redirects, not the creation flow. The creation flow is rare; redirects are constant.
TTL: Set Redis TTL to match your use case. For general URLs, 24 hours is reasonable. For URLs you know are temporary, match the expiry.
Cache invalidation: If a user deletes or updates a URL, invalidate the Redis key immediately. Don't wait for TTL expiry.
5. Lambda — Keeping Infrastructure Costs Low
Two Lambda functions handle the core logic:
URL Creation Lambda:
Validates the input URL (is it actually a URL? Is it safe?)
Generates the short code
Writes to DynamoDB
Returns the short URL
URL Redirect Lambda:
Checks Redis cache
Falls back to DynamoDB on cache miss
Returns a 302 redirect
Why Lambda over EC2 or ECS? For this workload, Lambda is ideal:
You pay per request, not per idle server
Auto-scales to millions of requests without configuration
No servers to manage or patch
The one concern with Lambda is cold starts. For the redirect function specifically, cold starts add latency. Mitigate this with Provisioned Concurrency on the redirect Lambda — keep a pool of warm instances ready.
The Analytics Problem
Most tutorials ignore click analytics entirely. But it's one of the most requested features.
The naive approach — incrementing a counter in DynamoDB on every redirect — is dangerous at scale. At 10,000 redirects/second on one URL, you'll hit DynamoDB write throughput limits and slow down redirects.
Better approach: Decouple analytics from the redirect path.
Redirect Lambda
│
└──► Kinesis Data Firehose (async, non-blocking)
│
▼
S3 (raw events)
│
▼
Athena (query analytics on demand)
The redirect happens immediately. The analytics event is fired asynchronously. The user never waits for analytics to complete.
For real-time dashboards, add a stream processor between Kinesis and a time-series store like DynamoDB or InfluxDB.
Handling Scale: The Numbers
Let's validate this architecture against real numbers.
Assumptions:
100 million redirects per day
1 million new URLs created per day
Average URL size: 200 bytes
Storage: 1M URLs/day × 200 bytes × 365 days = ~73GB/year. DynamoDB handles this trivially.
Redirect throughput: 100M/day = 1,160 requests/second average, with peaks 10x higher (12,000 rps). With CloudFront caching popular URLs, most of this never hits your Lambda functions.
Cost estimate (rough):
CloudFront: ~$10-15/month at this scale
Lambda: ~$20-30/month
DynamoDB (on-demand): ~$50-100/month depending on cache hit rate
ElastiCache (small instance): ~$30/month
Total: ~$100-150/month for a system handling 100 million redirects per day. That's the power of serverless-first architecture.
What I'd Skip in V1
Not everything needs to be built on day one. Here's what I'd defer:
Custom domains (e.g.
company.com/abc) — complex to implement, add laterLink previews / Open Graph — nice to have, not essential
Real-time analytics dashboard — build the data pipeline first, the UI later
Multi-region active-active — unless you have users on multiple continents from day one, start single-region and expand
The architecture above scales to hundreds of millions of requests before you need to rethink it. That buys you time to learn what your users actually need before over-engineering.
Key Takeaways
Reads dominate writes — design your caching strategy around the redirect path, not the creation path
Use 302, not 301 — browser caching of 301s will haunt you
Decouple analytics — never let analytics slow down the critical path
Short code generation is harder than it looks — think carefully about collision probability and enumeration attacks
CloudFront is doing more work than your servers — invest time in your cache invalidation strategy
What Would You Change?
This is one way to approach it — not the only way. I've made deliberate tradeoffs here that might not fit every use case.
What would you design differently? Would you choose a different database, a different caching strategy, or a different approach to short code generation?
Drop your thoughts in the comments — I read every one.
If you found this useful, follow me on LinkedIn where I post about system design, AWS, and engineering career growth every week.