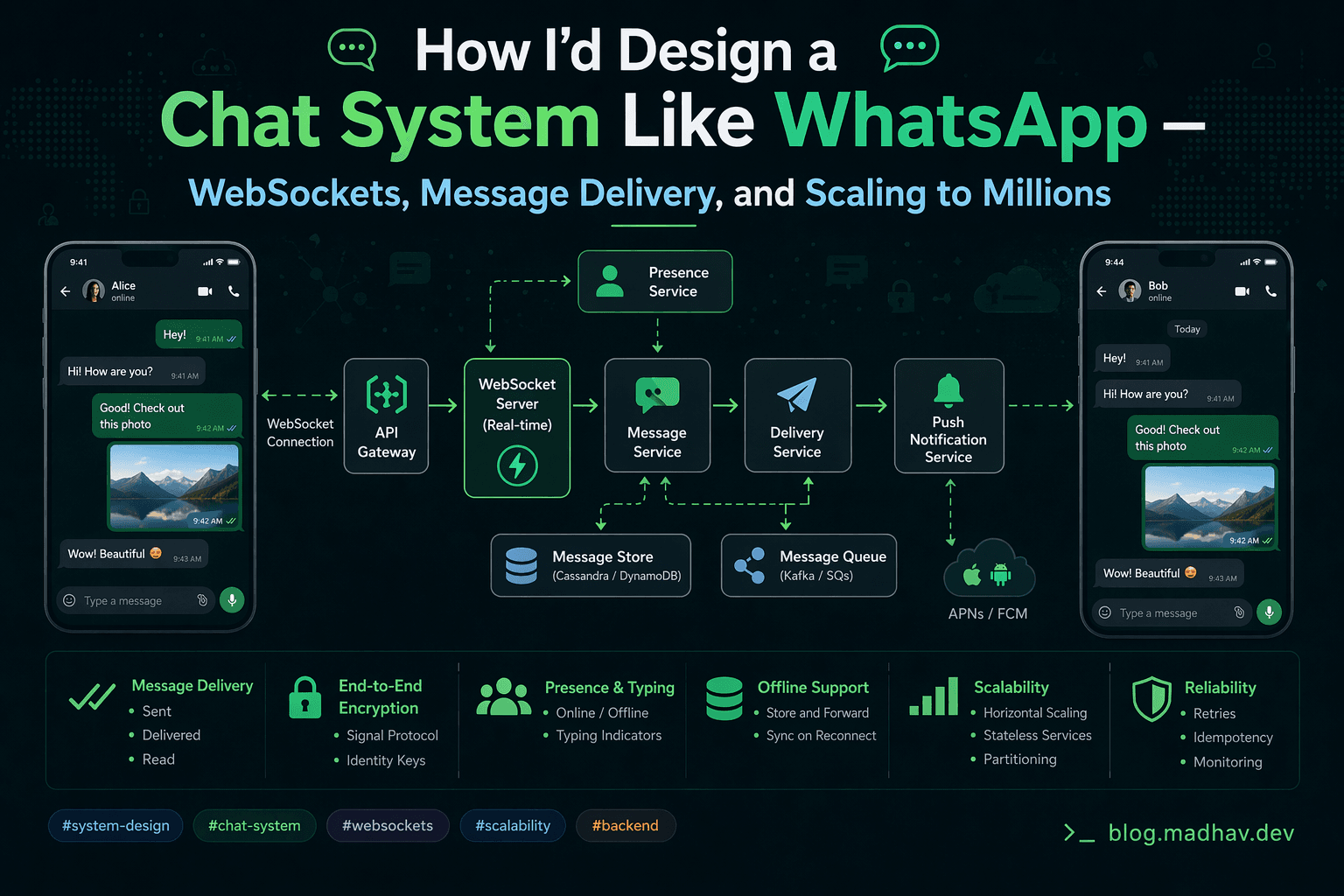
What Most Chat System Design Articles Get Wrong
Search "design a chat system" and you'll find hundreds of articles. Most of them give you a box labeled "Chat Server" with some arrows pointing at a database and call it a day.
That's not a design. That's a diagram with no decisions in it.
The real challenge in designing a chat system isn't the happy path — it's everything that goes wrong. What happens when a user goes offline mid-message? How do you guarantee a message sent to a group of 500 people actually reaches all of them? What does "delivered" even mean at scale?
This post covers the full architecture for a WhatsApp-style chat system supporting 1-on-1 and group messaging — with real decisions, real tradeoffs, and the three technical problems that will define your design: WebSockets, message delivery guarantees, and scaling to millions of concurrent users.
Requirements
Before touching architecture, let's be precise about what we're building.
Functional requirements:
1-on-1 messaging between users
Group messaging (up to 500 members per group)
Message delivery receipts (sent, delivered, read)
Online/offline presence indicators
Message history persistence
Media sharing (images, files) — basic support
Non-functional requirements:
Low latency — messages should feel real-time (under 100ms end-to-end)
High availability — 99.99% uptime, chat can't go down
At-least-once delivery — no message ever silently lost
Eventual consistency — slight delay in delivery receipts is acceptable
Scale — 50 million daily active users, 100 messages per user per day = 5 billion messages per day
Let's use these constraints to drive every architectural decision.
The Naive Approach (And Why It Fails)
The obvious first attempt:
User A → HTTP POST /messages → Server → Database → Poll for new messages → User B
User B polls every few seconds asking "any new messages?" This works for email. It's catastrophic for chat.
At 50M users polling every 3 seconds:
16.6 million requests per second — just for polling
Most responses are empty — wasted compute
Minimum latency is your polling interval — 3 seconds feels broken for chat
You need persistent connections. Enter WebSockets.
Part 1: WebSockets — The Foundation of Real-Time Messaging
How WebSockets Work
HTTP is request-response — the client always initiates. WebSockets upgrade an HTTP connection to a persistent, bidirectional channel. Once established, either side can send data at any time.
Client Server
│ │
│── HTTP GET /chat ──────────► │
│ Upgrade: websocket │
│◄─ 101 Switching Protocols ── │
│ │
│ ◄──── persistent connection ────► │
│ │
│◄── {"type":"message",...} ── │ (server pushes)
│── {"type":"ack",...} ────────►│ (client responds)
The connection lifecycle:
# FastAPI WebSocket endpoint
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from typing import Dict
import json
app = FastAPI()
class ConnectionManager:
def __init__(self):
# user_id → WebSocket connection
self.active_connections: Dict[str, WebSocket] = {}
async def connect(self, user_id: str, websocket: WebSocket):
await websocket.accept()
self.active_connections[user_id] = websocket
await self.update_presence(user_id, online=True)
async def disconnect(self, user_id: str):
self.active_connections.pop(user_id, None)
await self.update_presence(user_id, online=False)
async def send_to_user(self, user_id: str, message: dict) -> bool:
websocket = self.active_connections.get(user_id)
if websocket:
await websocket.send_json(message)
return True
return False # User offline — message needs queuing
async def update_presence(self, user_id: str, online: bool):
# Publish to Redis pub/sub so other servers know
await redis.publish(
f"presence:{user_id}",
json.dumps({"user_id": user_id, "online": online})
)
manager = ConnectionManager()
@app.websocket("/ws/{user_id}")
async def websocket_endpoint(websocket: WebSocket, user_id: str):
await manager.connect(user_id, websocket)
try:
while True:
data = await websocket.receive_json()
await handle_message(user_id, data)
except WebSocketDisconnect:
await manager.disconnect(user_id)
The Problem With WebSockets at Scale
A single server can maintain roughly 65,000 concurrent WebSocket connections (limited by OS file descriptors). At 50M DAU with 20% concurrently online, that's 10M concurrent connections — requiring 153+ chat servers just to hold connections.
This creates the core architectural challenge: User A's connection is on Server 1. User B's connection is on Server 7. How does a message from A reach B?
The answer is a message broker acting as the backbone between servers.
The Architecture
Here's the full system:
┌─────────────────────────────┐
│ Clients │
│ (WebSocket connections) │
└──────────┬──────────────────┘
│
┌──────────▼──────────────────┐
│ Load Balancer │
│ (sticky sessions by user) │
└──────────┬──────────────────┘
│
┌────────────────────┼────────────────────┐
│ │ │
┌──────▼──────┐ ┌────────▼──────┐ ┌───────▼──────┐
│ Chat Server│ │ Chat Server │ │ Chat Server │
│ #1 │ │ #2 │ │ #3 │
└──────┬──────┘ └──────┬────────┘ └──────┬───────┘
│ │ │
└──────────────────┼────────────────────┘
│
┌────────▼────────────┐
│ Message Broker │
│ (Kafka / SQS) │
└────────┬────────────┘
│
┌──────────────────┼────────────────────┐
│ │ │
┌──────▼──────┐ ┌──────▼──────┐ ┌───────▼──────┐
│ Message │ │ Presence │ │ Push Notif │
│ Storage │ │ Service │ │ Service │
│ (DynamoDB) │ │ (Redis) │ │ (APNs/FCM) │
└─────────────┘ └─────────────┘ └──────────────┘
Component Responsibilities
Load Balancer — Sticky Sessions
Route each user to the same chat server for the duration of their session. This keeps WebSocket connections stable and avoids re-routing overhead. Use consistent hashing on user_id.
Chat Servers — Connection Holders
Each chat server does three things:
Maintains WebSocket connections for its assigned users
Receives incoming messages and publishes to the message broker
Subscribes to the message broker and delivers messages to connected users
Message Broker (Kafka)
The backbone. Every message flows through Kafka, which provides:
Guaranteed delivery between chat servers
Replay capability for debugging
Fan-out for group messages
Decoupling of send and receive paths
Message Storage (DynamoDB)
Persistent message history. DynamoDB's access pattern fits perfectly — you almost always query by conversation_id to get recent messages.
Presence Service (Redis)
Tracks who is online. Redis pub/sub broadcasts presence changes to all interested servers in real time.
Push Notification Service
When a recipient is offline, route to APNs (iOS) or FCM (Android) instead of a WebSocket.
Part 2: Message Delivery Guarantees — The Hard Part
This is where most system design discussions stop too early. Let's go deeper.
The Three Guarantees
At-most-once: Message is sent once. If delivery fails, it's not retried. Messages can be lost. Never acceptable for chat.
At-least-once: Message is retried until acknowledged. Messages might be delivered multiple times (duplicates). Acceptable if you handle deduplication.
Exactly-once: Message is delivered precisely once, no duplicates, no losses. Theoretically ideal. In practice, extremely hard to implement correctly across distributed systems.
For chat systems: target at-least-once delivery with client-side deduplication.
The Message Flow With Delivery Guarantees
1. Sender assigns a client-generated idempotency key (UUID)
2. Message sent to Chat Server
3. Chat Server persists to DynamoDB (idempotency key as sort key)
4. Chat Server publishes to Kafka
5. Chat Server returns ACK to sender → sender marks as "sent" ✓
6. Kafka consumer delivers to recipient's Chat Server
7. Recipient's Chat Server delivers via WebSocket
8. Recipient's client sends ACK
9. Chat Server publishes delivery receipt to Kafka
10. Sender's Chat Server receives receipt → sender marks "delivered" ✓
11. Recipient opens conversation → "read" receipt sent
12. Sender marks "read" ✓
The idempotency key is critical. If step 3 succeeds but the server crashes before step 5, the sender will retry. Without an idempotency key, you get duplicate messages. With it, the database insert is a no-op on retry.
import uuid
from datetime import datetime
class Message:
def __init__(
self,
sender_id: str,
conversation_id: str,
content: str,
idempotency_key: str = None
):
self.message_id = str(uuid.uuid4())
self.idempotency_key = idempotency_key or str(uuid.uuid4())
self.sender_id = sender_id
self.conversation_id = conversation_id
self.content = content
self.timestamp = datetime.utcnow().isoformat()
self.status = "sent"
async def send_message(message: Message) -> dict:
# Idempotent write — if key exists, return existing record
try:
await dynamodb.put_item(
TableName="messages",
Item={
"conversation_id": {"S": message.conversation_id},
"message_id": {"S": message.message_id},
"idempotency_key": {"S": message.idempotency_key},
"sender_id": {"S": message.sender_id},
"content": {"S": message.content},
"timestamp": {"S": message.timestamp},
"status": {"S": "sent"}
},
ConditionExpression="attribute_not_exists(idempotency_key)"
)
except dynamodb.exceptions.ConditionalCheckFailedException:
# Already saved — idempotent, return success
pass
# Publish to Kafka regardless (Kafka consumer handles dedup)
await kafka_producer.send(
topic="messages",
key=message.conversation_id.encode(),
value=message.__dict__
)
return {"status": "sent", "message_id": message.message_id}
Handling Offline Users
When a recipient is offline, the message must not be lost. The flow changes:
async def deliver_message(message: dict, recipient_id: str):
# Try WebSocket first
delivered = await manager.send_to_user(recipient_id, message)
if not delivered:
# User offline — store in their message queue
await dynamodb.put_item(
TableName="offline_queue",
Item={
"user_id": {"S": recipient_id},
"timestamp": {"S": message["timestamp"]},
"message_id": {"S": message["message_id"]},
"message": {"S": json.dumps(message)}
}
)
# Send push notification
await push_service.notify(
user_id=recipient_id,
title=f"New message from {message['sender_id']}",
body=message["content"][:100]
)
async def on_user_connect(user_id: str):
# Drain offline queue on reconnect
queued = await dynamodb.query(
TableName="offline_queue",
KeyConditionExpression="user_id = :uid",
ExpressionAttributeValues={":uid": {"S": user_id}},
ScanIndexForward=True # oldest first
)
for item in queued["Items"]:
message = json.loads(item["message"]["S"])
await manager.send_to_user(user_id, message)
# Clear the queue
for item in queued["Items"]:
await dynamodb.delete_item(
TableName="offline_queue",
Key={
"user_id": {"S": user_id},
"timestamp": {"S": item["timestamp"]["S"]}
}
)
Part 3: Group Messaging — The Fan-Out Problem
1-on-1 messaging is a solved problem at this point. Group messaging is where things get genuinely hard.
The Fan-Out Challenge
When User A sends a message to a group of 500 people:
500 delivery operations need to happen
Members are spread across many chat servers
Some members are offline
Some members have the conversation muted
The operation needs to be fast from A's perspective
Two approaches:
Fan-out on write: When a message is sent, immediately write it to every member's inbox. Each member pulls from their own inbox.
Pros: Fast reads — inbox is pre-computed
Cons: Expensive writes — 500 writes per message
Wasteful for large groups with many inactive members
Fan-out on read: Store the message once. When a member opens the conversation, compute their view.
Pros: Single write per message, storage efficient
Cons: Expensive reads — compute on every open
Slower first load for large groups
Hybrid approach (what WhatsApp actually uses):
For small groups (< 100 members): fan-out on write — fast delivery to active members
For large groups (100-500 members): store once, use Kafka partitions per group, let each member's server pull
SMALL_GROUP_THRESHOLD = 100
async def handle_group_message(message: Message, group_id: str):
# Get group members
members = await get_group_members(group_id)
if len(members) <= SMALL_GROUP_THRESHOLD:
# Fan-out on write — direct delivery
await fan_out_write(message, members)
else:
# Store once, publish to group topic
await store_message(message)
await kafka_producer.send(
topic=f"group.{group_id}",
value=message.__dict__
)
async def fan_out_write(message: Message, members: list):
# Publish one Kafka event per member
tasks = [
kafka_producer.send(
topic=f"user.{member_id}",
value=message.__dict__
)
for member_id in members
if member_id != message.sender_id
]
await asyncio.gather(*tasks)
Group Delivery Receipts — Don't Do What iMessage Does
Showing individual read receipts for every member in a 500-person group is a scaling nightmare — 500 receipt events per message read.
Practical approach:
Store receipts as a bitmap or counter, not individual records
Show "Delivered to N members" rather than individual names
Only compute individual receipts for groups under 20 members
async def update_group_receipt(
message_id: str,
group_id: str,
user_id: str,
receipt_type: str # "delivered" or "read"
):
# Atomic increment — no race conditions
await dynamodb.update_item(
TableName="group_receipts",
Key={
"message_id": {"S": message_id},
"group_id": {"S": group_id}
},
UpdateExpression=f"ADD {receipt_type}_count :inc",
ExpressionAttributeValues={":inc": {"N": "1"}}
)
DynamoDB Schema
The access patterns for chat are simple but the schema design matters enormously for cost and performance.
Table: messages
├── PK: conversation_id (String) ← partition by conversation
├── SK: timestamp#message_id (String) ← sort by time, unique
├── sender_id (String)
├── content (String)
├── message_type (String) ← text, image, video
├── status (String) ← sent, delivered, read
└── idempotency_key (String)
GSI: sender_id-timestamp-index
├── PK: sender_id
└── SK: timestamp
(For "messages sent by user" queries)
Table: conversations
├── PK: user_id (String)
├── SK: last_message_timestamp (String)
├── conversation_id (String)
├── participant_ids (List)
└── unread_count (Number)
Table: offline_queue
├── PK: user_id (String)
└── SK: timestamp (String)
Key design decisions:
Partition by conversation_id not user_id — conversations are the natural unit of access
Use composite sort key timestamp#message_id — enables time-range queries and guarantees uniqueness even for messages sent at the same millisecond
TTL on offline_queue — auto-expire after 30 days so storage doesn't grow unbounded
Presence System
Real-time online/offline indicators are deceptively complex at scale.
The naive approach: Query the database for last-seen timestamp on every profile view. At scale, this creates a read hotspot.
Better approach: Redis with TTL + pub/sub
PRESENCE_TTL = 60 # seconds
async def heartbeat(user_id: str):
# Client sends heartbeat every 30 seconds
# Server refreshes TTL — if it expires, user is offline
await redis.setex(
f"presence:{user_id}",
PRESENCE_TTL,
"online"
)
async def is_online(user_id: str) -> bool:
return await redis.exists(f"presence:{user_id}") == 1
async def subscribe_to_presence(user_ids: list, callback):
# Subscribe to presence changes for a list of users
# Used to update UI in real time when contacts go online/offline
pubsub = redis.pubsub()
channels = [f"presence:{uid}" for uid in user_ids]
await pubsub.subscribe(*channels)
async for message in pubsub.listen():
if message["type"] == "message":
await callback(json.loads(message["data"]))
Presence at scale consideration: Don't broadcast presence to all followers. WhatsApp only shows presence to mutual contacts — and even then, only when the user opens a conversation. This limits the fan-out to manageable levels.
Scaling to Millions of Users
The Numbers
| Metric |
Value |
| Daily Active Users |
50 million |
| Concurrent connections (20%) |
10 million |
| Messages per day |
5 billion |
| Messages per second (peak 3x avg) |
~174,000 |
| Average message size |
1 KB |
| Storage per day |
~5 TB |
Horizontal Scaling Plan
Chat servers: Stateless except for active WebSocket connections. Scale horizontally — add servers as concurrent connections grow. Target: 50,000 connections per server = 200 servers at peak.
Kafka: Partition by conversation_id. This ensures all messages in a conversation are ordered and processed by the same consumer. Use 1,000 partitions — allows scaling to 1,000 parallel consumers.
DynamoDB: Serverless — scales automatically. At 174,000 writes/second, provision ~200,000 WCU with auto-scaling. Cost at this scale: ~$35,000/month. Optimise with DynamoDB Accelerator (DAX) for read-heavy workloads like message history.
Redis (Presence): Use Redis Cluster. Shard by user_id. At 10M concurrent users, each key is ~100 bytes = ~1GB total — fits comfortably in a 3-node Redis cluster.
Geographic Distribution
For a global user base, co-locate users with the closest region:
User in Singapore → AP-Southeast Chat Servers → AP Kafka Cluster
User in London → EU-West Chat Servers → EU Kafka Cluster
Cross-region messages:
AP Kafka → Cross-region replication → EU Kafka → EU Chat Server → User
Use AWS Global Accelerator to route users to the nearest chat server cluster. Accept ~50ms cross-region latency for international messages — it's acceptable and much cheaper than a single global cluster.
Never send media through the chat server. It'll saturate your WebSocket connections.
The right approach:
1. Client requests a pre-signed S3 URL from the media service
2. Client uploads directly to S3 (bypasses chat server entirely)
3. Client sends a message containing the S3 object key
4. Recipient's client downloads directly from CloudFront (CDN)
import boto3
from botocore.config import Config
s3 = boto3.client(
's3',
config=Config(signature_version='s3v4')
)
async def get_upload_url(
user_id: str,
file_type: str,
file_size_bytes: int
) -> dict:
# Validate file size (50MB limit)
if file_size_bytes > 50 * 1024 * 1024:
raise ValueError("File too large")
object_key = f"media/{user_id}/{uuid.uuid4()}"
presigned_url = s3.generate_presigned_url(
'put_object',
Params={
'Bucket': 'chat-media-bucket',
'Key': object_key,
'ContentType': file_type,
'ContentLength': file_size_bytes
},
ExpiresIn=300 # 5 minutes to complete upload
)
return {
"upload_url": presigned_url,
"object_key": object_key,
"cdn_url": f"https://cdn.yourdomain.com/{object_key}"
}
This keeps your chat servers lean — they only handle small JSON payloads, never binary data.
What I'd Skip in V1
Not everything needs to be built on day one:
End-to-end encryption — Signal Protocol is complex. Add it in V2 once the core is stable.
Voice and video calls — WebRTC is a separate system entirely. Separate service, separate team.
Message reactions — Nice to have. A simple DynamoDB list attribute works until you have emoji reaction analytics requirements.
Message editing and deletion — Soft delete first (mark as deleted), hard delete later when compliance requirements are clear.
Multi-device sync — Start with single-device. Multi-device sync (like WhatsApp Web) is a significant engineering effort involving device registration and message fan-out to device sets.
Key Takeaways
WebSockets are necessary but not sufficient — you also need a message broker between servers to route messages across your fleet
Target at-least-once delivery with client-side deduplication — exactly-once is theoretically appealing but practically expensive
Idempotency keys are non-negotiable — retries without them create duplicate messages
Fan-out strategy depends on group size — write fan-out for small groups, read fan-out for large ones
Never route media through chat servers — S3 pre-signed URLs + CloudFront keep your servers fast
Presence is a separate problem — Redis TTL + pub/sub, not a database column
Partition Kafka by conversation_id — preserves message ordering within a conversation
DynamoDB partition key is conversation, not user — conversations are the natural unit of access in chat
What Would You Design Differently?
Every chat system has its own constraints. Some teams prioritise encryption above all else. Others need to support 10,000-member broadcast channels. Some operate in regions where push notifications are unreliable.
What's the trickiest chat-related engineering problem you've encountered? Drop it in the comments — I read every one.
Follow me on LinkedIn for weekly posts on system design, AWS, and engineering career growth.